






Google ogłosiło to we wtorek Lumieregenerator wideo AI o nazwie „Model dyfuzji czasoprzestrzennej do generowania realistycznego wideo” w Dołączony arkusz wstępnego wydruku. Ale nie oszukujmy się: świetnie radzi sobie z tworzeniem filmów z uroczymi zwierzętami w głupich sytuacjach, takich jak jazda na rolkach, prowadzenie samochodu czy gra na pianinie. Jasne, może więcej, ale jest to prawdopodobnie najbardziej zaawansowany jak dotąd generator wideo wykorzystujący sztuczną inteligencję do zamiany tekstu na zwierzęta.
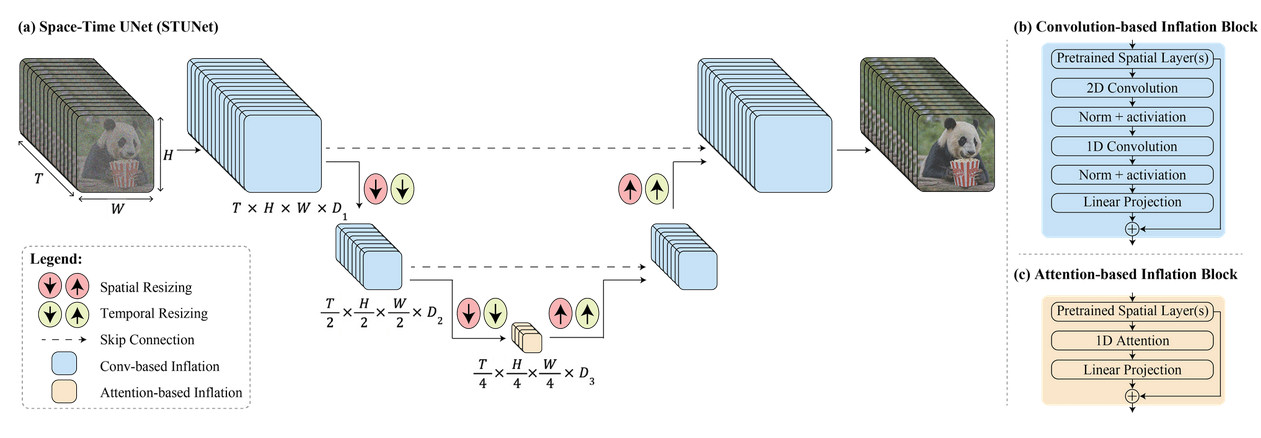
Według Google Lumiere wykorzystuje unikalną strukturę do generowania całego filmu za jednym razem. Lub, jak to ujęła firma: „Oferujemy architekturę U-Net przestrzenno-czasową, która generuje cały czasowy czas trwania filmu jednocześnie, w ramach jednego przejścia w modelu. Jest to w przeciwieństwie do istniejących modeli wideo, które składają się na duże odległości klatki kluczowe, po których następuje rozdzielczość superczasowa – „Jest to podejście, które utrudnia osiągnięcie globalnej spójności czasowej”.
Mówiąc laikiem, technologia Google została zaprojektowana tak, aby obsługiwać jednocześnie aspekty przestrzeni (miejsca, w których znajdują się rzeczy w filmie) i czasu (jak rzeczy poruszają się i zmieniają w trakcie filmu). Zamiast więc tworzyć wideo poprzez zszycie wielu małych części lub klatek, można utworzyć cały film od początku do końca w jednym, płynnym procesie.
Oficjalny film promocyjny towarzyszący artykułowi „Lumiere: model dyfuzji przestrzenno-czasowej do generowania wideo” opublikowany przez Google.
Lumiere potrafi również wykonywać wiele trików imprezowych, które są ładnie przedstawione na przykładach Strona demonstracyjna Google. Na przykład może dokonać konwersji tekstu na wideo (przekonwertować pisemną zachętę na wideo), konwertować nieruchome obrazy na klipy wideo, tworzyć filmy w określonych stylach przy użyciu obrazu referencyjnego, stosować spójną edycję wideo za pomocą podpowiedzi tekstowych i tworzyć Segmenty filmowe Przesuwając określone obszary obrazu i wyświetlając wideo com.inpainting Zdolności (na przykład mogą zmienić rodzaj sukni, którą dana osoba nosi).
W artykule Lumiere badacze Google podali, że model sztucznej inteligencji produkuje pięciosekundowe filmy w rozdzielczości 1024 x 1024 pikseli, którą określają jako „niską rozdzielczość”. Pomimo tych ograniczeń badacze przeprowadzili badanie użytkowników i stwierdzili, że wyniki Lumiere'a były lepsze od modeli syntezy wideo opartych na sztucznej inteligencji.
Jeśli chodzi o dane szkoleniowe, Google nie powiedział, skąd wziął filmy, które umieścił w Lumiere, pisząc: „Trenujemy nasze własne urządzenie T2V”. [text to video] Modeluj na zbiorze danych zawierającym 30 milionów filmów wraz z podpisami tekstowymi. [sic] Filmy mają długość 80 klatek i 16 kl./s (5 sekund). Podstawowy model został wytrenowany na rozdzielczości 128 x 128.”
Wideo generowane przez sztuczną inteligencję jest wciąż w fazie początkowej, ale w ciągu ostatnich kilku lat jego jakość uległa poprawie. W październiku 2022 r. omówiliśmy pierwszy publicznie ujawniony model komponowania obrazu firmy Google – Imagen Video. Może tworzyć krótkie filmy w rozdzielczości 1280 x 768 z wiersza poleceń przy 24 klatkach na sekundę, ale wyniki nie zawsze były spójne. Wcześniej Meta zadebiutowała z własnym generatorem wideo AI, Make-A-Video. W czerwcu ubiegłego roku model komponowania wideo Gen2 firmy Runway umożliwił tworzenie dwusekundowych filmów na podstawie podpowiedzi tekstowych, tworząc surrealistyczne, satyryczne reklamy. W listopadzie omówiliśmy funkcję Stable Video Diffusion, która umożliwia tworzenie krótkich klipów ze nieruchomych obrazów.
Firmy zajmujące się sztuczną inteligencją często oferują generatory wideo przedstawiające urocze zwierzęta, ponieważ generowanie spójnych, niezniekształconych ludzi jest obecnie trudne, zwłaszcza że my, ludzie (jesteście ludźmi, prawda?) jesteśmy dobrzy w zauważaniu wszelkich niedoskonałości w ludzkich ciałach lub sposobie, w jaki się poruszają. Wystarczy spojrzeć na wygenerowanego przez sztuczną inteligencję Willa Smitha jedzącego spaghetti.
Sądząc po przykładach Google (a nie korzystając z nich sami), Lumiere wydaje się przewyższać inne modele tworzenia wideo oparte na sztucznej inteligencji. Ponieważ jednak Google ma tendencję do trzymania swoich modeli badawczych nad sztuczną inteligencją blisko piersi, nie jesteśmy pewni, kiedy społeczeństwo będzie miało szansę samemu je wypróbować.
Jak zawsze, gdy widzimy, że modele syntezy tekstu na wideo stają się coraz wydajniejsze, nie możemy powstrzymać się od myśli… Przyszłe implikacje Dla naszego społeczeństwa internetowego, które opiera się na dzieleniu się elementami medialnymi i ogólnym założeniu, że „realistyczne” wideo zwykle przedstawia rzeczywiste rzeczy w rzeczywistych sytuacjach uchwyconych kamerą. Bardziej wydajne przyszłe narzędzia Lumiere do komponowania wideo sprawią, że tworzenie zwodniczych deepfakesów stanie się niezwykle łatwe.
W tym celu badacze napisali w sekcji „Wpływ społeczny” artykułu Lumiere: „Naszym głównym celem w tej pracy jest umożliwienie początkującym użytkownikom tworzenia treści wizualnych w kreatywny i elastyczny sposób. [sic] Istnieje jednak ryzyko nadużycia w celu tworzenia fałszywych lub szkodliwych treści przy użyciu naszej technologii i uważamy, że konieczne jest opracowanie i wdrożenie narzędzi do wykrywania uprzedzeń i szkodliwych przypadków użycia, aby zapewnić bezpieczne i uczciwe korzystanie.

„Chcę być miłośnikiem telewizji. Certyfikowany entuzjasta popkultury. Stypendysta Twittera. Student amator.”
More Stories
TRUE NORTH uruchomiła nową platformę marki „Life’s Different After” w ramach kampanii Today the Brave
Pomiar mowy ciała Wiadomości o Mirażu
W trakcie testu | Rower Giant Revolt 2025 ma dodatkowe schowki w dolnej rurze i twierdzi, że zapewnia większy komfort